I am attempting to annotate my 16S community using GreenGenes instead of SILVA in order to run my data through the PICRUSt tool. I noticed this tool states that the community must be annotate/aligned using the Greengenes reference OTUs (18May2012 version).
I have been searching around the web and I am unable to find a greengenes file from the specified date/version. The closest dates to the one specified I have found is a file from May 2013 and one from August 2012. Other than these no other date is close.
I was wondering if anybody could possibly share a greengenes file from May 2012, or is there a typo in the PICRUSt description which should say 2013 instead of 2012?
Hello,
I’ve been using Microbiomanalyst for the past 4 years for several analyses and the recent update on PICRUST seems to not work on my samples anymore.
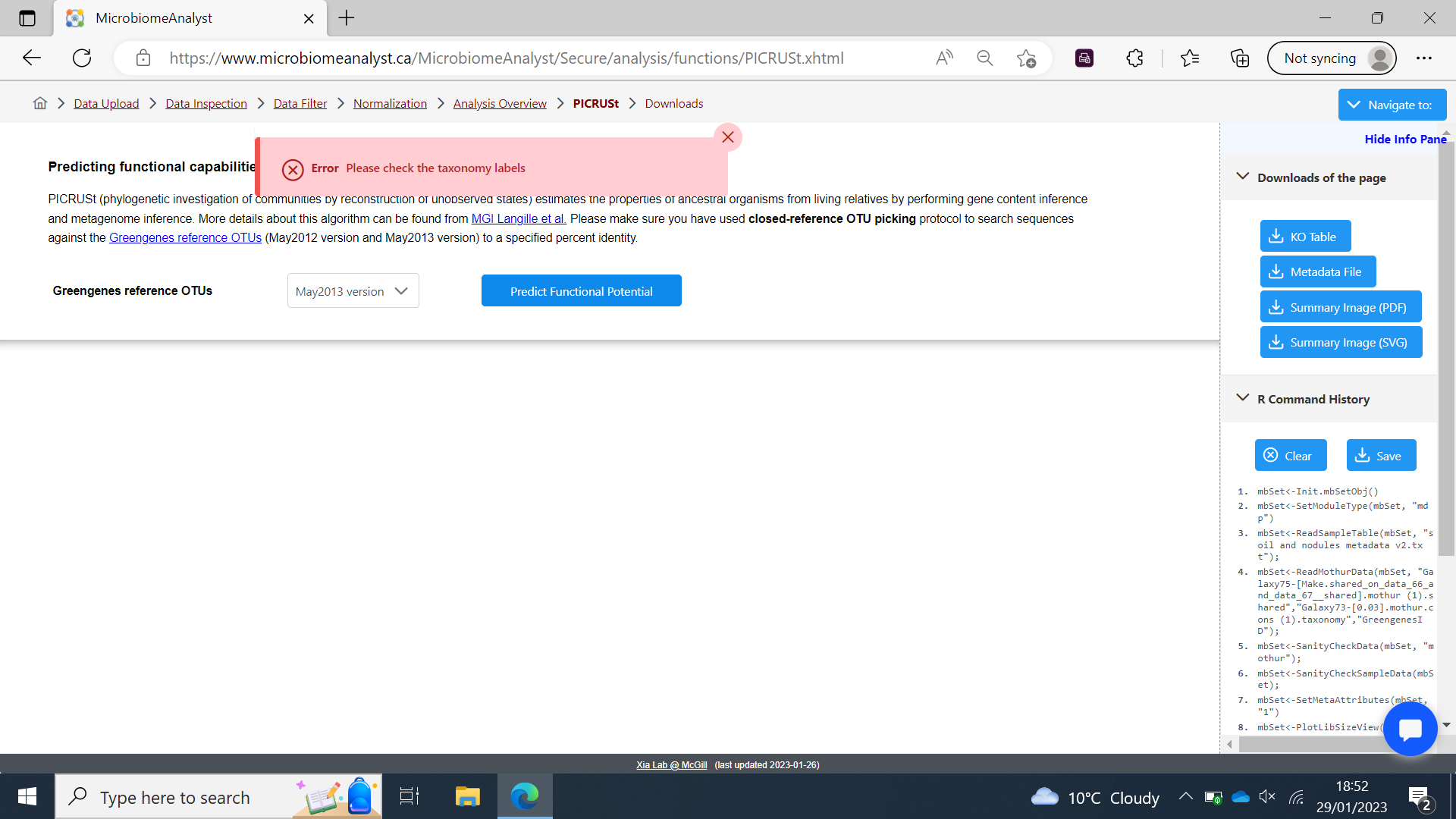
I’m attaching a screenshot of the error. Please let me know what would be the problem.
@Yao that’s great thanks for confirming that. Unfortunately like @Helga_jenifer I am having the same issue with PICRUSt and I am getting the same error message regarding the taxonomy labels.
Any help would be fantastic, thanks for your help so far already, Ryan
1 - Which tool and which module
PICRUSt using the May 2013 reference database, on the marker data profiling tool
2 - Provide a copy of your data, or indicate which example data you used
attached below is the metadata file, taxonomy file and shared file output from the Mothur pipeline I have used for annotation/alignment. NOTE for the taxonomy and shared file I had to change the file type to a txt file in order to successfully upload the file to the forum, but I checked the files after doing this and they look essentially the same so I think no change has been done to the formatting or contents. I also had to cut down the size of the taxonomy and make shared files due to limitations in the size of the uploads I can do, I have provided the first few lines of each file type so you can see how they are formatted etc. If you need the full files could you possibly suggest a method in which to send these?
3 - Document all steps leading to the issue. Sometimes screenshots may be necessary
Uploaded Mothur files and metadata file to the marker data profiling tool using the mothur tab and select greengenes taxonomy labels (attempted to use PICRUSt with both of the options for greengenes, neither was successful). Proceed through the usual steps in the marker data profiling tool e.g. data check, filtering, rarefaction etc. At end of marker data profiling tool, select PICRUSt from list of possible analysis methods, receive error message stating “error please check taxonomy labels”
4 - If it is about using R packages, please provide the environment information, such as sessionInfo()
N/A
Hello, thanks for providing the files. The files (abundance table and taxonomy table) are in the wrong format if you changed to use the .txt format. You can follow the related example to make it right, or you can share with me original files by email (yao.lu5@mail.mcgill.ca).
The files I uploaded to the forum here, I had to change to .txt in order to upload them to the forum. When I attempted to run them on MicroBiomeAnalyst there were ran in the correct format, as taxonomy files and shared files respectively.
I have emailed you across a copy of the files in the correct formats, as outlook does not have any restrictions on the file types that can be sent through email.
Hello, I have checked your data.
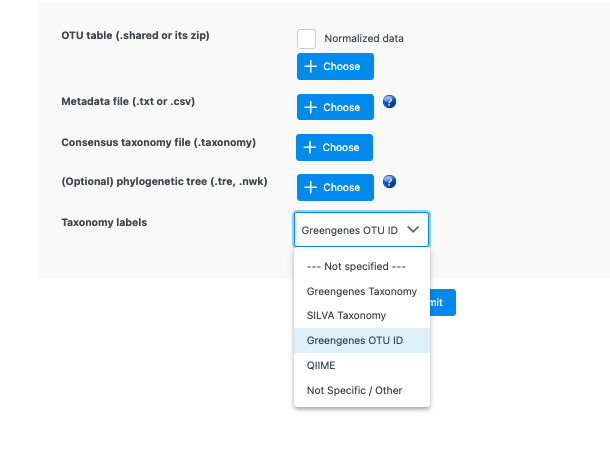
I think you choose the wrong Taxonomy labels in the upload page. As the taxonomy table is also provided, your otu table only contain OTU IDs. So you need to choose Greengenes OTU ID as the screenshot below: .
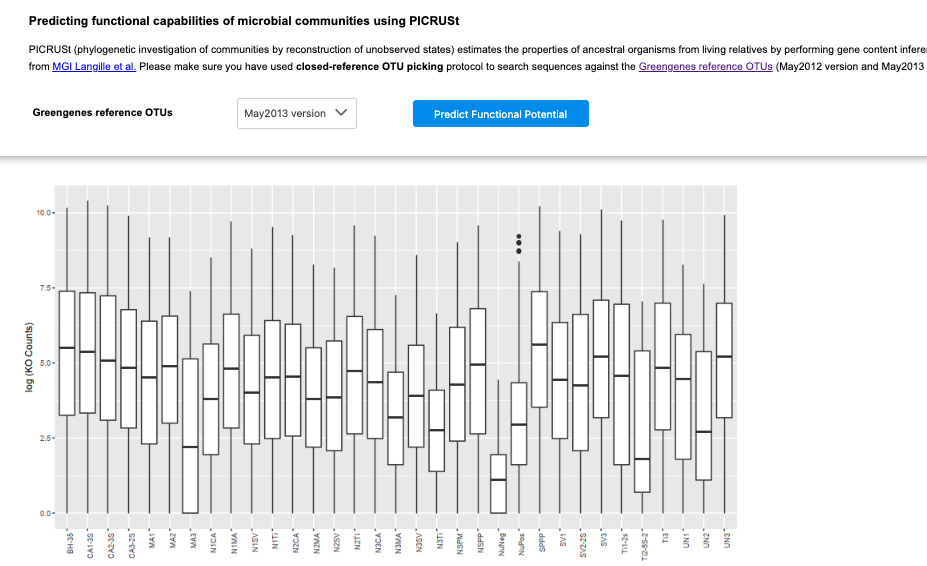
It works well from my side, the result is shown below:
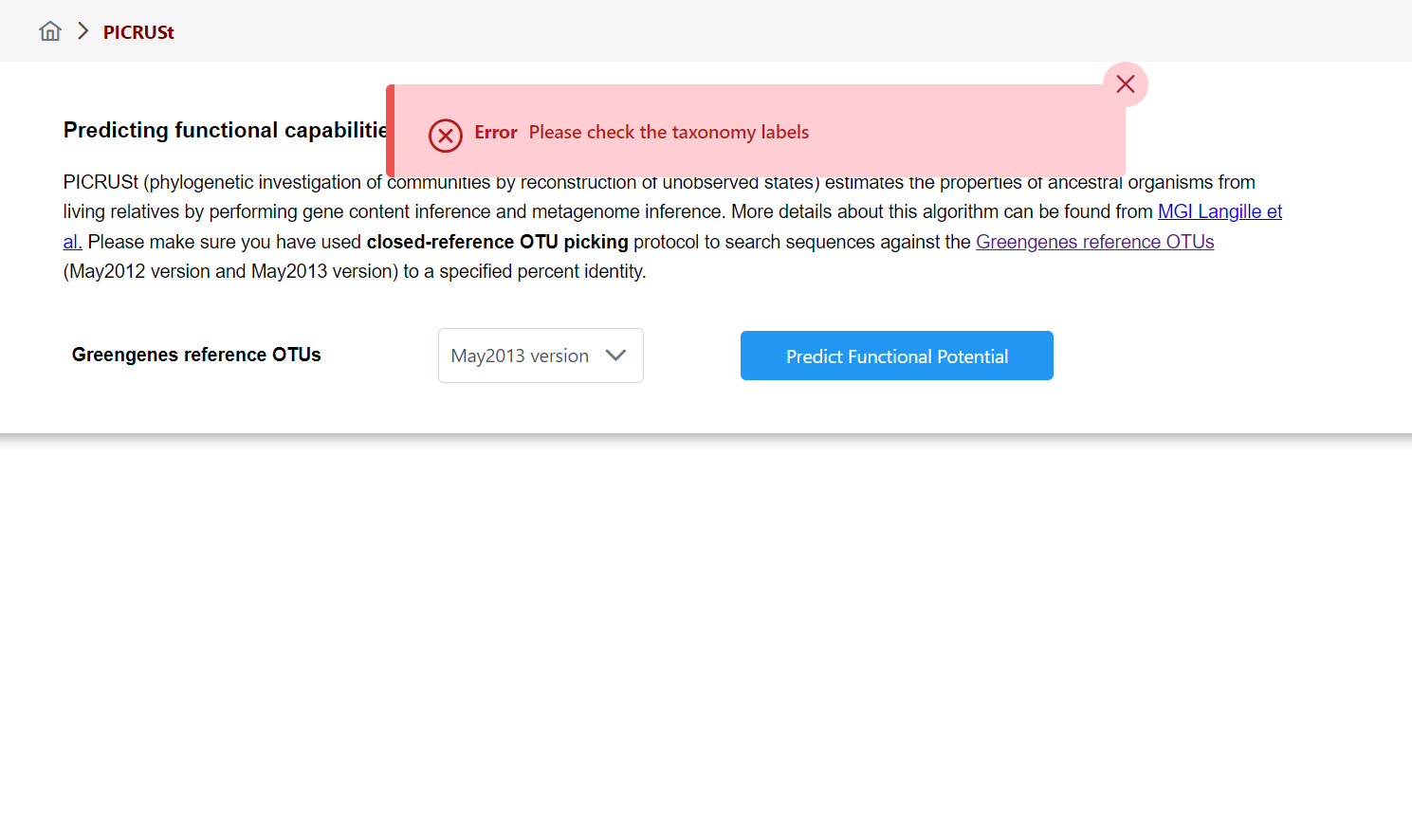
This is all very odd as I attempted it with Greengenes OTU ID selected and I am still getting the same error message which I have attached the in the screen below.
I will detail the steps I am following in order to upload the files and attempting to generate the PICRUSt output so you can see what I am doing and spot if I am doing anything incorrect.
select marker data profiling
2 . select MOTHUR output tab and upload the shared file, metadata file and taxonomy file under the respective buttons (the same files I emailed to you), select greengenes OTU ID as the taxonomy label. press submit then proceed to next step.
check data integrity check, all sample names match (metadata vs. OTU table): yes, number of samples is the same (33) on the four bottoms metrics, do data integrity looks to be okay. proceed.
on data filtering, low count filter: minimum count = 0, Prevalence in samples (%) = 10. low variance filter, percentage to remove (%) = 0, based on = interquartile range. These options are selected as I dont want any data to be removed as I have previously done filtering steps on the MOTHUR pipeline. press submit then proceed.
data normalisation: do not rarefy, do not scale ad do not transform data. As want to see the predicted functionality of all groups in the sample, these may be removed by rarefaction etc. press submit then proceed.
on analysis overview, click PICRUSt (greengenes), select May 2013 for greengenes reference OTUs, press predict functional potential.
At this point the error message is generate that can be seen in the above screenshot.
Any help regarding this would be appreciated as it is most puzzling.
Thanks, Ryan
 .
.