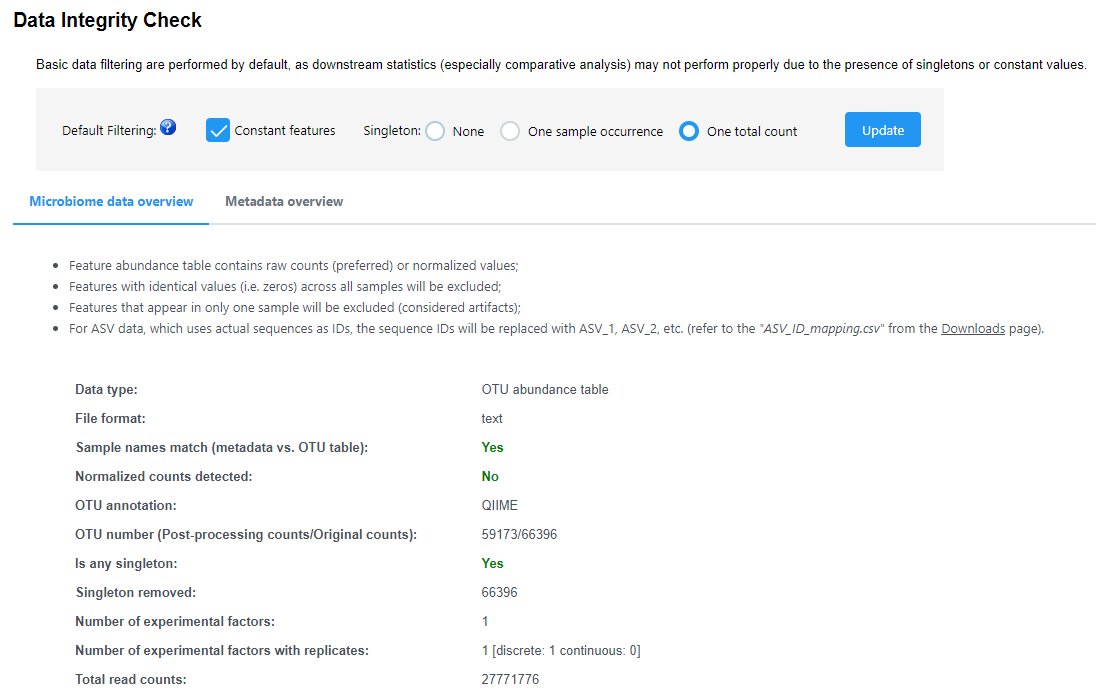
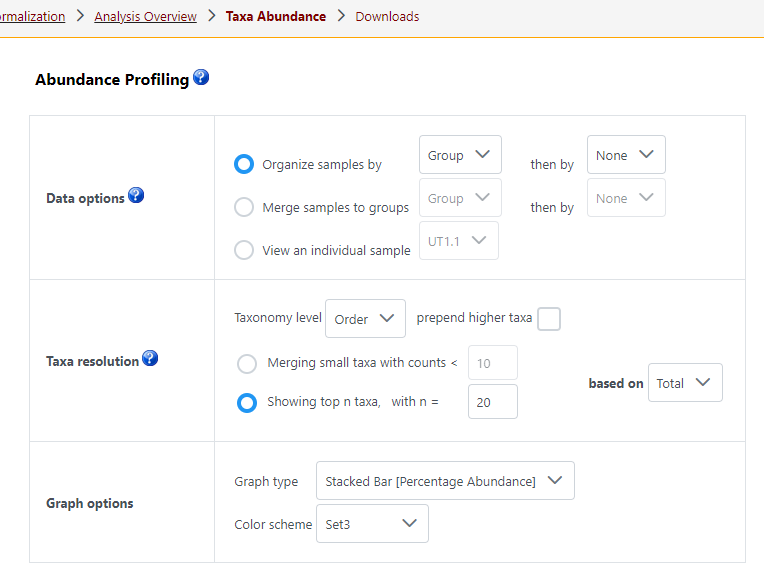
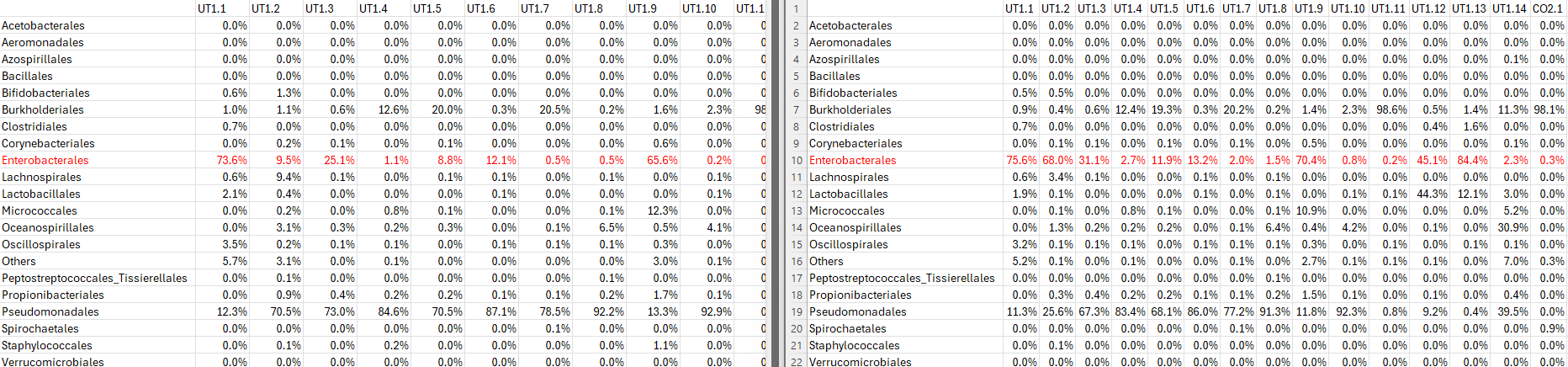
In Meta Data Profiling of MicrobiomeAnalyst 2.0, I applied the same filtering conditions on the same data set, but the numbers generated from the Abundance table in Taxa abundance are different every time I start over by uploading data files. Where does this randomness come from? Sorry if I am missing something.
There are randomness in data filtering step. For instance, if you remove 10% based on IQR (inter-quantile range), those with IQR ranked at the lower 10% will be removed. However, many features will have same values. How to break a tie? See below
Thank you so much for this Xia. This is very helpful.
I wonder if it might be good idea to remove this randomness in this low variance filtering step because we need consistency in the results when using this filter in terms of reproducibility point of view. Consistency in results might be more important than what features are filtered out because it won’t have much effect on the results whichever those low variance features are filtered out. Also it will be easier to keep consistency in the results throughout the analyses without this random filtering because sometimes it’s hard to get all results from onetime data uploading. This is just my suggestion. Hope this makes sense. Thanks!
This choice is a conscious decision - features that are unstable are generally not good candidates for biomarkers. If you look for consistency and robustness in features, I would suggest to choose default (one sample occurrence) in step one (instead of one total counts).
We do offer Pro version to allow subscribed users to define their own workflows (i.e. lock down all parameters). The community tool is more for exploratory data analysis (EDA) to reveal different aspects of users’ data.