The dimension reduction algorithms find sets of multi-dimensional components that explain the maximum variance within individual 'omics data sets, and are maximally related across 'omics data sets. The loading scores for each component reveals the features that contribute most towards these components. Therefore the top # of features within these top components are important for multi-omics integrative analysis. The main motivation here is to help understand the top # features using correlation networks.
You can adjust how many features are selected in the Analysis Overview & Parameter Tuning page:
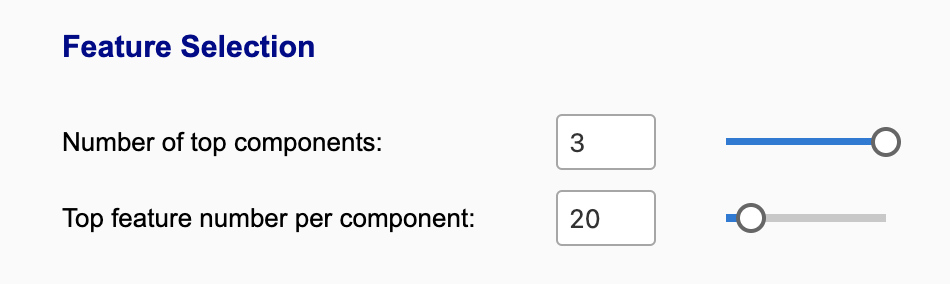
The first slider specifies the number of top components that features are selected from. The second slider specifies the number of top features of each 'omics type that are taken from each component, based on the ranked abs(loading scores). Thus, in this case, 20 features from each 'omics are selected from the top three components: 20 features * 2 'omics types * 3 components = 120 features used for network construction. Note that some features may be shared across different components, and thus the total feature numbers will be less than 120.